
随着存储向云数据库系统的持续迁移,此类系统中慢查询对服务和用户体验的影响日益加剧。根因诊断在促进慢查询检测和优化方面发挥着不可或缺的作用。本文提出了一种方法,能够识别导致慢查询的可能根因类型,并根据其加速慢查询的潜力对其进行排序。这使得能够优先处理影响最大的根因,从而提高慢查询优化的效率。为了实现更准确和精细的诊断,我们提出了 RCRank(Ranking for the Root Causes of slow queries) 框架,该框架将根因分析建模为多模态机器学习问题,并利用来自查询语句、执行计划、执行日志和关键性能指标的多模态信息。为了从异构多模态输入中获取具有表达力的嵌入,RCRank 集成了自监督预训练,以增强跨模态对齐和任务相关性。接下来,该框架结合了根因自适应跨 Transformer,使其能够自适应地融合具有不同特性的多模态特征。最后,该框架采用统一模型,并设计了考虑影响力的训练目标,用于识别和排序根因。我们在真实和合成数据集上进行了实验,结果表明 RCRank 在根因识别和排序方面能够稳定超越当前最先进的方法,并在多项评估指标上均表现出色。
作者: 欧阳彪,张颖莹,成涵吟,树扬,郭晨娟,杨彬,文青松,范伦挺, Christian S. Jensen
关键词:
根因诊断,多模态数据,云数据库
论文链接:
https://arxiv.org/abs/2503.04252
代码链接:
https://github.com/decisionintelligence/RCRank
1. 引言
企业和个人正越来越多地将其数据库服务迁移到云端。然而,云数据库系统的性能问题,特别是慢查询,会给用户带来经济损失,并降低用户对云端数据管理的信任。因此,加速慢查询对于确保高性能的云数据库系统至关重要。慢查询可能源于数据库系统的内部因素,如缺少相关索引或 SQL 语句书写不当,也可能受到外部因素的影响,如 I/O 瓶颈和网络问题。本文的目标是提供一个框架帮助用户解决慢查询问题,重点关注由内部因素引起的根因。识别根因,即识别导致慢查询的关键因素,然后根据根因的重要程度,通过相应的优化方法提升数据库性能。尽管已有方法针对慢查询的识别,但仍然存在两个主要限制:
限制一:侧重于根因类型识别。 现有方法主要关注识别慢查询的根因类型。然而,这并不能完全满足优先处理“最重要”根因的需求。基于根因优化慢查询的成本较高,如果针对每个根因都进行修正,可能会带来巨大的开销。因此,在选择要处理的根因时,考虑其影响力(即解决该根因后可节省多少运行时间)是十分重要的。然而,根因识别(RCI)方法无法量化解决已识别根因的潜在影响,从而限制了其实用性。
限制二:云数据库系统的观测不完整性。 大多数现有方法依赖于单一模态的信息,例如 CPU 或内存使用时间等关键性能指标来识别根因,而忽略了其他能够提供慢查询内部因素见解的数据来源。例如,查询语句和执行计划包含关于查询目标和估计执行过程的信息,而执行日志记录了查询执行过程中消耗的资源及其执行状态。若要实现全面观测,需要综合考虑这些数据来源,以此构建更扎实的基础,从而更准确地理解慢查询及其根因,并提升根因识别的准确性。
2. 模型方法
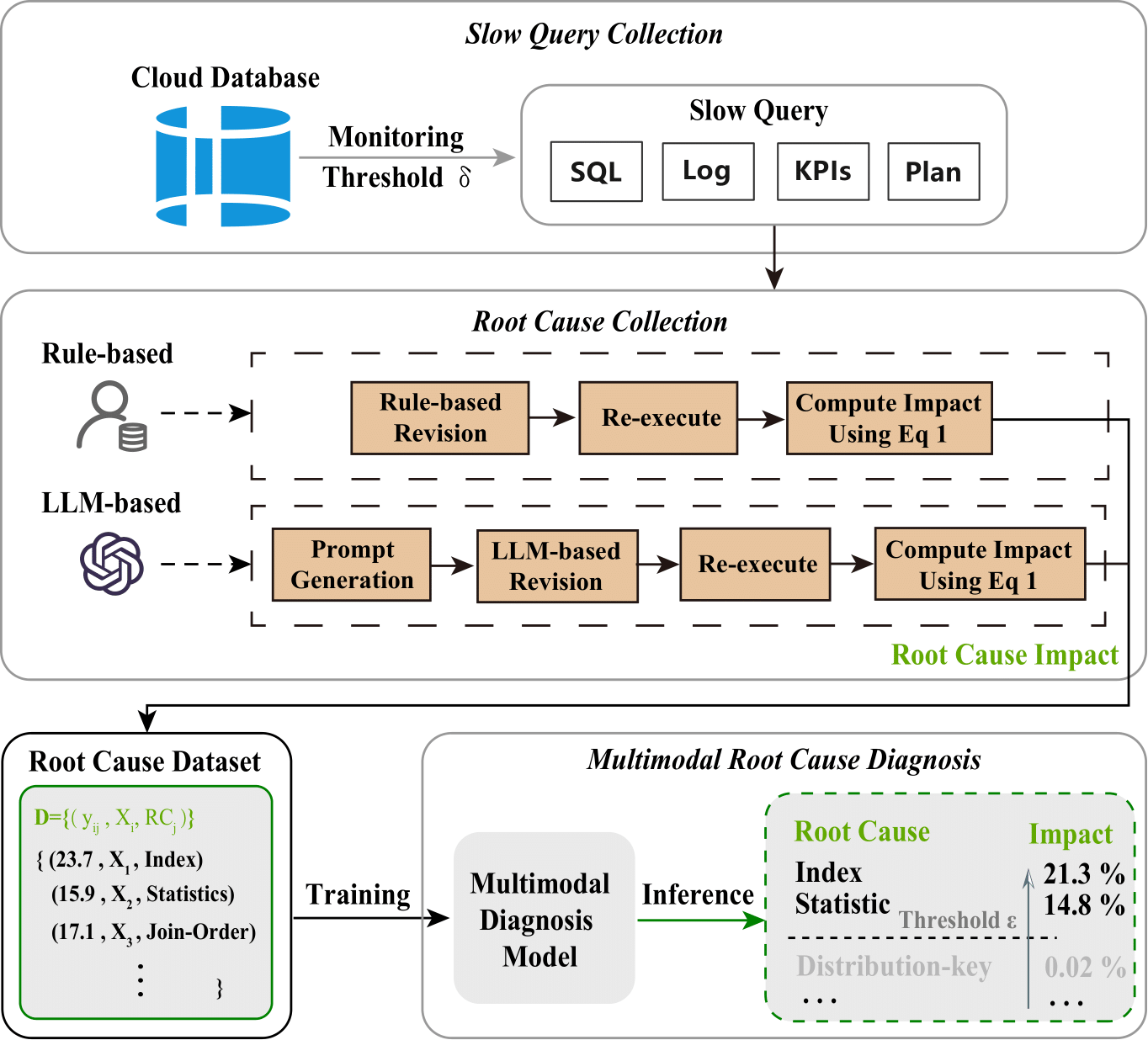
如图1所示,我们提出了一种多模态诊断框架,用于识别慢查询的根因并根据其影响力进行排序。具体来说包含以下几个关键方面:慢查询与根因收集模块包括云数据库系统监控、慢查询收集和根因收集。该模块收集慢查询及其对应根因的影响,为第二个模块提供数据基础。多模态根因诊断模块学习从未见过的慢查询和根因到根因对慢查询影响的估计值的映射关系,从而构建基于估计影响力的根因排序列表。
2.1 慢查询根因收集
如图1所示,慢查询收集通过云数据库监控系统对查询和数据库实例进行持续监控,并收集超过慢查询阈值的查询。根因收集通过基于规则的方法和基于大语言模型(LLM)的方法进行分析,以获取慢查询的根因。通过收集慢查询并根据与对应根因相关的方法对其进行优化,我们构建了一个用于识别和排序慢查询根因的数据集。
2.2 多模态根因诊断
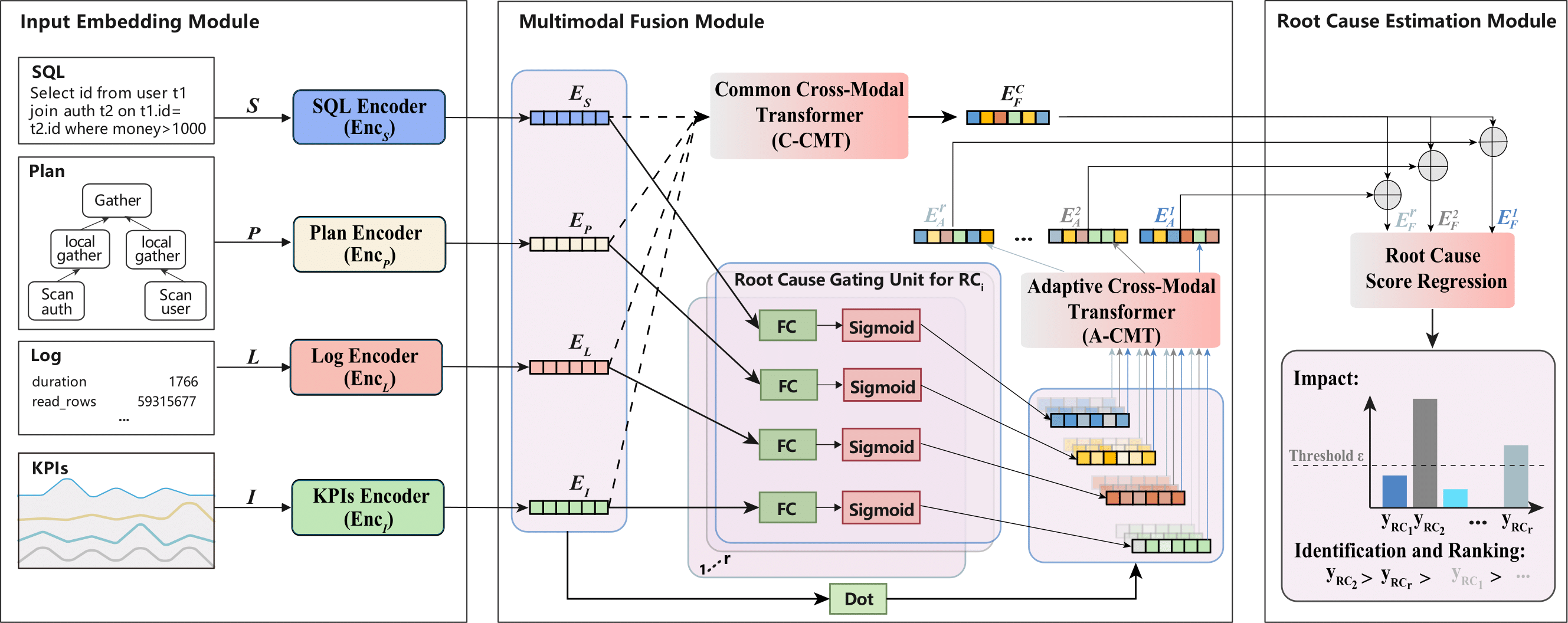
2.2.1 自监督预训练
输入嵌入模块为每种输入模态配备了独立的编码器。对于多模态输入数据 ,其中包括查询语句 、执行计划 、执行日志 和关键性能指标,编码器输出各模态的嵌入表示:
该模块的作用是将不同模态的异构输入编码到共享的嵌入空间,以便进一步特征提取。需要注意的是,该模型采用自监督预训练,这不仅减少了对标注根因数据的需求,还允许利用未标注的查询数据来获得更具表达力的嵌入表示。为了提升嵌入质量,以实现更好的跨模态对齐和任务相关性,并进一步降低对标注数据的需求,我们在输入嵌入中引入了自监督多模态预训练。
在多模态数据输入中,不同模态之间存在部分对应关系。例如,查询语句中的字段名、表名和过滤条件也出现在执行计划树中的节点中。同样,执行日志中的某些数据与计划的根节点数据相对应。受到这些多模态查询数据中对应关系的启发,我们提出了自监督预训练方法,以对齐不同模态并增强数据嵌入的表达能力。以 SQL 模态为例,设为 其被掩码的内容, 为剩余内容。预训练的训练目标可以表示为:
KPI模态包含关于当前数据库状态的信息。考虑到数据库状态对查询执行的影响,捕捉数据库状态的时间特征以及不同数据库实例度量之间的交互模式至关重要。KPI表示数据库状态,我们探索其时间特性。为了捕捉度量中的模式,我们单独预训练度量的嵌入。受此特性的启发,我们提出采用自编码结构和KPI时间序列重构作为预训练目标:
2.2.2 根因模态自适应
随着查询变得更复杂(例如,查询语句更长、执行计划中的节点更多、返回的行数更多、执行时间更长),只有一部分信息与慢查询高度相关,应该在诊断中重点关注。此外,不同的根因可能与多个模态的不同部分具有不同的关系。因此,我们根据根因自适应地融合多模态嵌入来诊断不同的根因。与根因的共性相关的特征,这些特征是所有根因共享的。我们使用共有特征交叉模态变换器(C-CMT)提取共享特征的融合表示()。为了提取每个根因的特定特征,我们使用自适应交叉模态变换器(A-CMT),根据不同的根因自适应地融合多模态嵌入():
2.2.3 统一识别和排序
为了在一个统一的框架中根据根因对慢查询的影响来识别和排序有效的根因,我们提出了一个用于估计每个潜在根因影响和排序的训练目标。根因影响估计的损失函数可以表示为:
然而,根因的识别可能会受到估计影响中的噪声的影响,尤其是在阈值附近的噪声,仅使用MSE损失来优化模型可能无法确保根因的准确排序。因此,我们需要根因有效性正则鼓励估计影响值大于或小于阈值𝜖,并且至少有一个边际距离𝜂,具体取决于根因是否有效。该正则化增强根因识别中区分有效与无效影响的能力。进一步的,根因顺序性正则约束了估计排序至少遵循真实排序之间的边际距离,从而保持根因的影响排名。
实验效果
我们分别在Hologres和Postgres数据库中收集真实和合成的根因数据集,并进行测试。表1、表2和表3分别展示了在根因识别和排序任务中, RCRank 在Holgores和Postgres数据库上的表现。我们使用粗体和下划线来分别突出表示最优和次优的表现。RCRank 在真实数据集和合成数据集上的所有指标性能表现都超过所有基线方法。

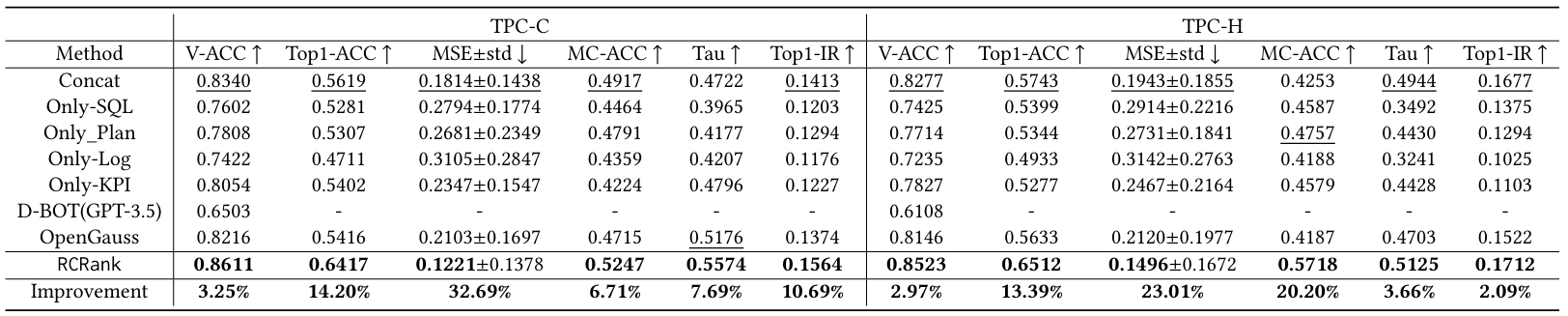
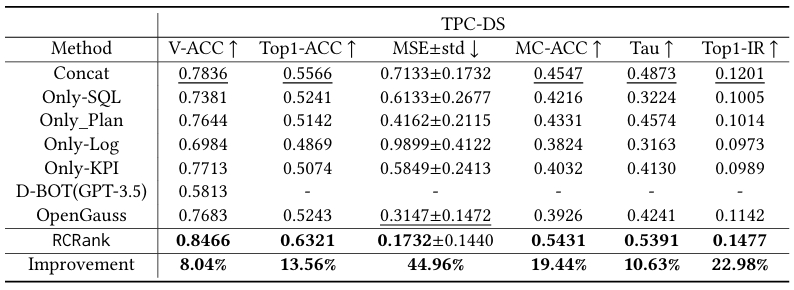
如表4所示,我们创建了四种 RCRank 变体,并在 Hologres 和 Postgres 上进行了多项实验,以比较它们对慢查询根因估计和排序性能的影响。w/o gate unit表示诊断不同的根因时,会关注查询语句中的部分 token、执行计划中的部分操作、日志中的部分数值以及 KPI 中的部分关键指标。我们从using MSE loss观察到对根因的排序和有效性施加约束可以增强对有效和关键根因的识别。同时,使用预训练帮助模型理解查询语句、执行计划和执行日志和KPI能够提升根因估计和排序的性能。

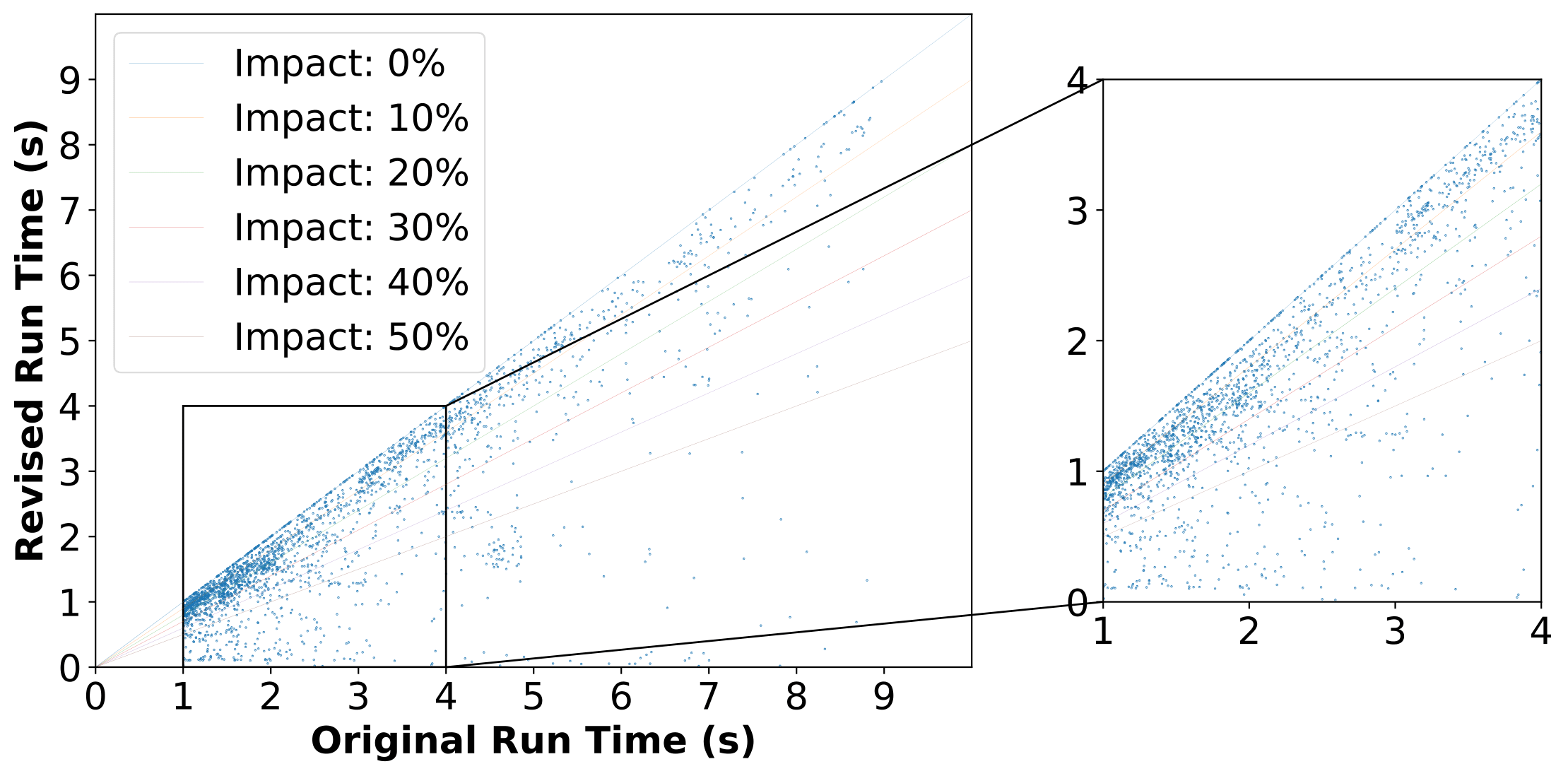
如图3所示,在大多数情况下,经过修改的慢查询的执行时间相比原始慢查询都有不同程度的缩短。RCRank 能够识别导致 Hologres 中查询大幅加速的根因。
结论
本文旨在识别慢查询的根因类型,并根据其对慢查询的影响进行排序。我们提出了一种针对慢查询根因的多模态排序框架(RCRank),将诊断过程建模为一个多模态机器学习问题,利用来自查询语句、执行计划、执行日志和关键性能指标的多模态信息。我们提出了一种多模态诊断模型,该模型能够通过模态对齐和任务相关性实现对异构模态的有效表达嵌入,采用高效且自适应的多模态特征融合,并统一执行根因的识别与排序。实验结果表明,我们的方法在根因识别和排序方面优于现有方法。未来的研究将重点探讨如何针对一组慢查询制定最佳的修改方案,以及如何高效地对 RCRank 进行增量训练,以包含新的根因。